

Jak pewnie wiesz, na co dzień łączę Big Data i Cybersecurity. Czy taka fuzja ma sens? Niektórzy nie do końca rozumieli czemu przechodzę do CSIRT’u. Przecież to różne bajki. Oj byli w błędzie… wolumen danych jest ogromny. Jest też sporo wyzwań. Zapraszam Cię do mojego wywodu na ten temat 😉.
Five V’s of big data
Popatrzmy na cyberbezpieczeństwo pod kątem popularnej piątki:
- Volume – Urządzenia sieciowe, serwery i stacje użytkowników potrafią wyprodukować niesamowite ilości danych. Nietrudno przedobrzyć. Musimy dobrze zdefiniować co zbieramy i odpowiednio przygotować pliki konfiguracyjne. Ważna jest również odpowiednia retencja. Nie wiadomo kiedy będziemy musieli sięgnąć po dane historyczne.
- Velocity – Szybkość dostarczenia wartości jest bardzo ważna w tej działce. Chcemy wykryć zagrożenia jak najszybciej i nie dopuścić do eskalacji problemu.
- Variety – Dane dostajemy z różnych źródeł i w różnych formatach. Może to być syslog, dzienniki Windows, netflow, zdarzenia z systemów bezpieczeństwa (Firewall, IDS, IPS, DLP, EDR etc.), a także informacje typu Threat Intelligence.
- Veracity – Oczywiście wszystko powyższe powinno być odpowiedniej jakości. Im lepsze dane (czyste i wzbogacone), tym szybszy proces analizy i detekcji. Ważna jest również kwestia normalizacji, często nazywam to wspólnym mianownikiem. Chodzi mianowicie o zgodność nazw pól i ich typów oraz możliwość pivot’owania z jednego źródła na kolejne podczas inwestygacji.
- Value – Wartością biznesową w tym przypadku będzie bezpieczeństwo monitorowanych systemów, czyli skuteczność detekcji.
Architektura
Porównajmy generyczną architekturę Big Data oraz tę zawartą w projekcie HELK. Jest to projekt umożliwjaący zaawansowaną analitykę w domenie cyber. Bazuje na Elastic Stack, Apache Kafka i Apache Spark… co przypadkowo jest również moją specjalnością 😅.
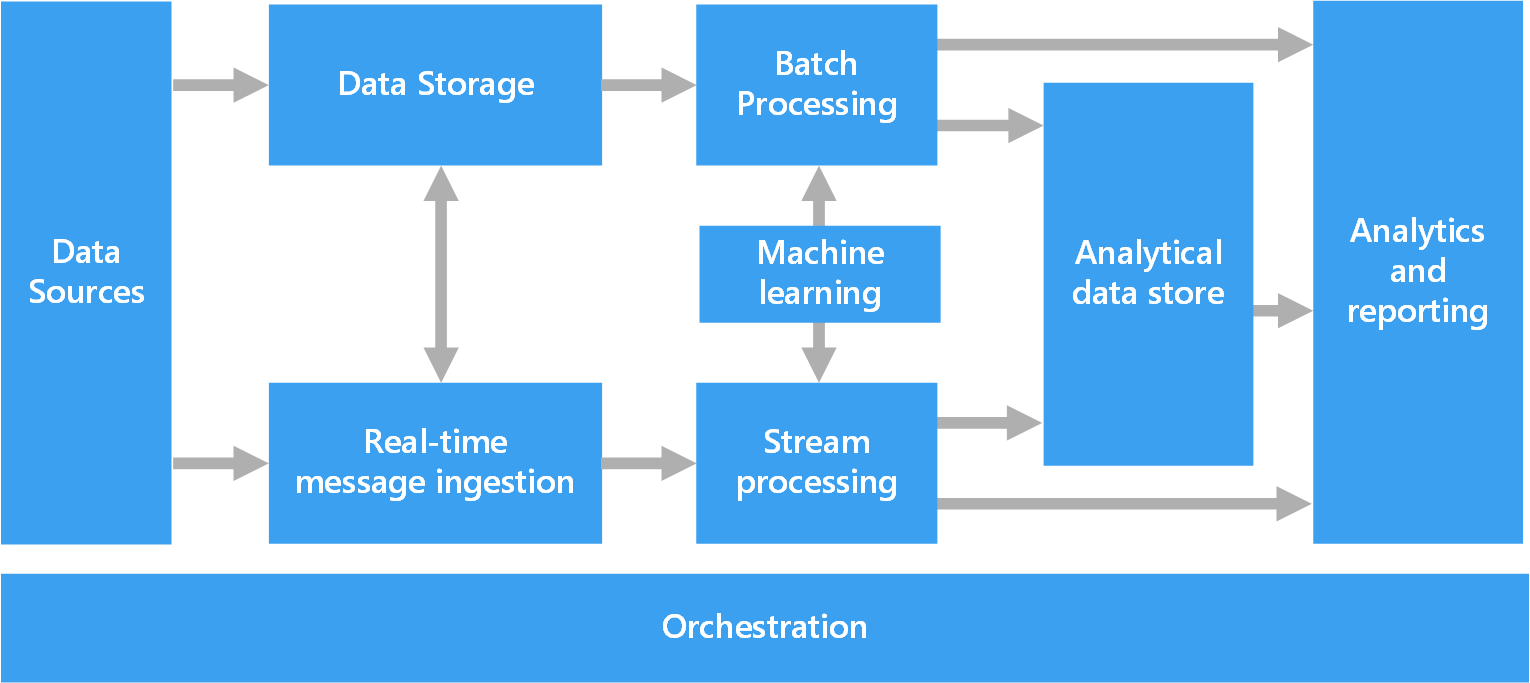
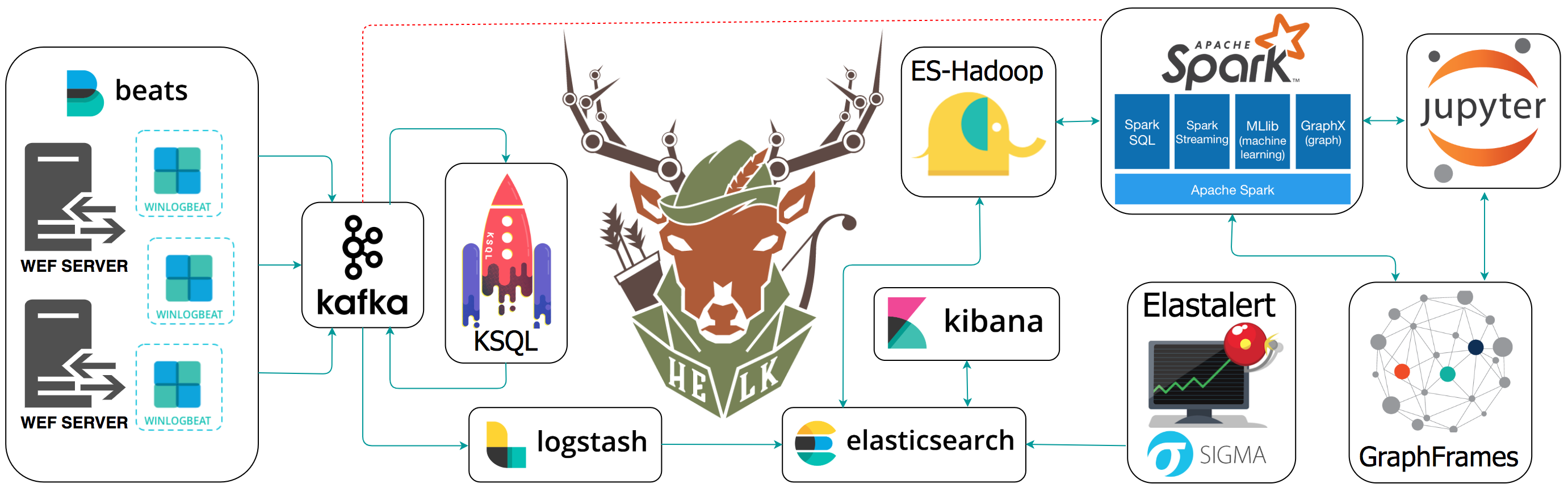
Kolekcja danych
Na diagramie przedstawione są agenty Winlogbeat i serwery WEF. To tylko drobne przykłady. W praktyce mamy spory wybór w tej kwestii. Wykorzystanie Apache Kafka jako bufor zapewnia nam elastyczność, potrzebujemy tylko czegos co potrafi gadać z Kafką np. Flutend, Logstash czy Kafka Connect. Forwardery od Splunka nie potrafią… ale można wrzucić coś co będzie pośredniczyć 😉.
Data lake / cold storage
Zastosowanie Kafki odwraca zależności. To nie Kafka wysyła dane, tylko konsumenci subskrybują dane z Kafki. Umożliwia to dodawanie kolejnych grup konsumentów. Możemy przekierować strumień danych do innych systemów. Na pewno przyda się forma Data Lake / long term storage dla danych np oparta o HDFS/S3/ADLS/GCS. Trzymanie danych z przed lat w SIEM może być kosztowne.
Czy w świecie cyber jesteśmy narażeni na bagienko (Data Swamp)? Jak najbardziej! Źródła powinny być starannie przygotowane, opisane, a przede wszystkim sensowne. Łatwo “utopić się” w danych. Nie wszystkie informacje są istotne z perspektywy analityka SOC.
Przetwarzanie strumieniowe
W ekosystemie Elastic Stack, Logstash pełni rolę strumieniowego przetwarzania danych. Możemy nim przetwarzać parsować i wzbogacać dane. Ważna jest jakość danych i normalizacja pól i wartości. Wpływa to bezpośrednio na szybkość i jakość prac anlitycznych.
Nie przepadasz za Logstashem? Weź Fluentd lub Vector’a. Brakuje zaawansowanych możliwości agregacji i łączenia strumieni? Weź ksqldb w parze z Kafka Connect. Poruszyłem ten temat tutaj. Wolisz Sparka lub NiFi? Weź Sparka lub NiFi 😎.
Przetwarzanie wsadowe
W większości przypadków wystarczy zwykły pythonowy notebook w Jupyter, ale gdy potrzebujesz coś więcej.. Apache Spark to uniwersalny rozproszony silnik przetwarzania danych. Taki AK-47 w świecie Big Data 😉. Potrzebujesz danych pod raport lub model ML? Wyciągniesz je z Kafki, Elasticsearch’a, S3 i wielu innych, zakręcisz, połączysz, wymieszasz, zostawisz na noc i rano masz elegancki dataset. W HELK zauwazyć można też podejście grafowe, a mianowicie Graphframes.
Machine Learning
Potencjał jest tutaj dość spory. Przykładowe wykorzystanie ML w Cybersecurity to DGA (detekcja C2’ek), wykrywanie anomalii w ruchu sieciowym i zachowaniu użytkownika. Możemy działać batchowo i strumieniowo, w czasie rzeczywistym.
SIEM / Data Warehouse / Analytical Data Store / Search Engine
Moim konikiem jest Elastic Stack, więc moją ulubioną platformą analityczną jest Elasticsearch w parze z Kibaną. To jednak nie ma znaczenia. Chodzi mi o sam fakt wystąpienia warstwy danych i narzędzi analitycznych. Umożliwiają tworzenie wizualizacji, dashboardów, zestawień, raportów i szybkie wyszukiwanie danych. Narzędzia i metody znane w Business Intelligence i Observability/DevOps/SRE.
Reguły detekcji
Charakterystyczym elementem wyróżniającym SIEM od standardowych baz i narzędzi analitycznych jest silnik reguł detekcji. Moduł ten pozwala na definiowanie i wykonywanie w zadanych interwałach czasowych konkretnych zapytań i agregacji. Choć jak się zastanowić… czy nie jest to mechanizm podobny do alertów z działu Observability, znanych przez adminów?
Intelligence-Driven SOC
Security to nie tylko dane z naszych systemów, ale również dane “wywiadowcze”, czyli CTI (Cyber Threat Intelligence). Są to informacje o potencjalnych zagrożeniach, adwersażach, kampaniach i IoC (Indicator of Compromise). IoC są to artefakty, które mogą świadczyć o włamaniu. Najczęściej są to adresy IP, domeny, hashe i charakterystyczne URL’e.
Akcja – Reakcja, czyli orchiestracja i automatyzacja
Orchiestracja i automatyzacja kojarzy mi się z Apache Airflow… i nawet go używamy! 😁 Jest wiele rzeczy któe można zautomatyzować. Po co ręcznie generować raporty, skoro może to za nas zrobić skrypt? Temat automatyzacji w branży cybersec to osobny temat. Popularnym narzędziem jest XSOAR.
Wnioski
Cybersecurity to ciekawa domena pod kątem przetwarzania danych, analityki i architektury. Skala i problemy są niespotykane, a praca nietuzinkowa i interesująca. Według mnie będzie coraz większe zapotrzebowanie na tego typu umiejętności i interdyscyplinarność. Jesteśmy w stanie permanentnej cyberwojny, a jak ktoś nie wierzy, niech wystawi jakąś usługę na publicznym adresie 😁.

Jeden komentarz do “Big Data + Cyberbezpieczeństwo = Data-Driven SOC”